

Sparse Mixture of Experts reduces up to 50 percent of computational cost, optimizes parameter usage and improves continual learning performance in large-scale AI models.
Sparse Mixture of Experts, an optimized variant of MoE
In large-scale AI systems, scaling model capacity without increasing computational cost is a core challenge. The Mixture of Experts architecture addresses this by partitioning the model into multiple experts, where each expert specializes in a subset of the data space.
Sparse Mixture of Experts emerges as a more efficient variant. Instead of activating all experts, SMoE selectively activates only a small subset of the most relevant experts for each input. This preserves high model capacity while significantly reducing computational overhead.
An important extension is Sparse Mixture of Prompt Experts, where the SMoE mechanism is integrated into prompt tuning to address continual learning challenges.
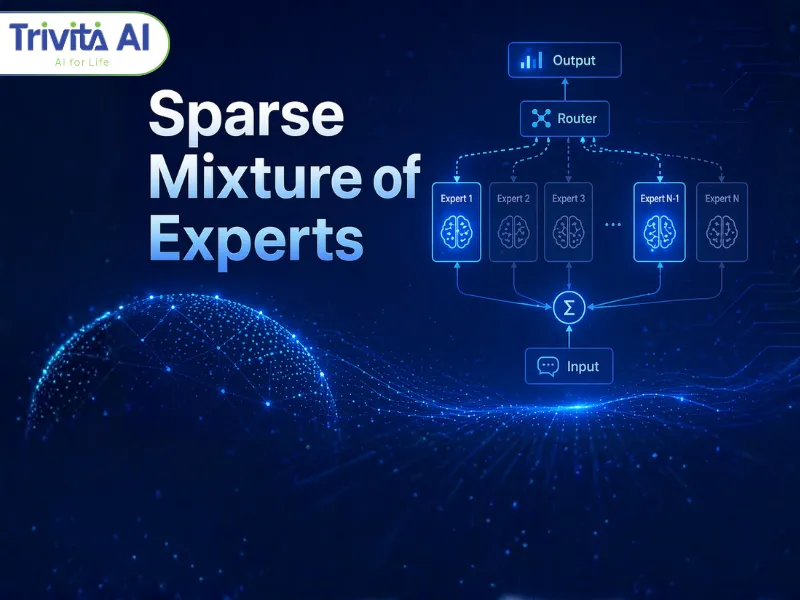
Mechanism of operation
The core of Sparse Mixture of Experts lies in intelligent routing between experts.
The gating mechanism determines which experts are selected for a given input. Instead of processing the entire model, only a subset of experts with the highest scores is activated, typically following a Top-K strategy.
To optimize efficiency, SMoE employs a score aggregation mechanism. A pooled representation of the input is used to compute a proxy score for each expert, reducing complexity compared to token-level computation.
Additionally, adaptive noise is introduced to ensure balanced utilization of experts. Without this mechanism, the system may collapse to using only a few experts, reducing overall effectiveness.
Performance and resource efficiency
Experimental results demonstrate that Sparse Mixture of Experts achieves strong performance across both efficiency and accuracy dimensions.
In terms of trainable parameters, architectures such as SMoPE use approximately 0.38 million parameters, significantly fewer than alternatives like Deep L2P++ with 4.78 million parameters or CODA-Prompt with nearly 4 million parameters. This highlights high parameter efficiency.
Regarding computational cost, SMoE can reduce up to 50 percent of required operations during both training and inference. For example, a configuration may reduce computational load from approximately 67.44 GFLOPs to 33.72 GFLOPs while maintaining or improving accuracy.
Another critical aspect is computational complexity. By leveraging proxy scoring, expert selection complexity is reduced from O(Ndk) to O(dk), enabling scalability without proportional cost increase relative to the number of experts.
Standard configuration of SMoE
In typical experimental setups, Sparse Mixture of Experts is configured with several key parameters.
The total number of experts is often set to 25, while only 5 experts are activated per input. This balances model capacity and computational efficiency.
Experts are commonly integrated into early attention blocks of the backbone model, such as Multi-Head Self-Attention layers in Vision Transformer architectures.
The backbone model is typically pretrained on large-scale datasets, enabling knowledge reuse and faster adaptation.
Read more:
Specialized technical mechanisms
Several supporting mechanisms contribute to the effectiveness of Sparse Mixture of Experts.
Adaptive noise is tuned at an appropriate level, typically around 0.4, balancing exploration of new experts and system stability.
The sparse gating mechanism improves routing efficiency by using proxy scores instead of full-data computation, reducing cost while enhancing system stability during scaling.

Experimental results and applications
Results across multiple benchmarks demonstrate the practical effectiveness of Sparse Mixture of Experts.
Accuracy reaches high levels across datasets such as ImageNet-R at approximately 79.32 percent, CIFAR-100 at around 89.23 percent and CUB-200 at about 87.43 percent, indicating strong generalization capability.
Another notable strength is resistance to catastrophic forgetting. In continual learning scenarios involving sequential tasks, SMoE maintains stable performance without significant degradation, a common issue in many traditional models.
An optimized direction for large-scale AI and continual learning
The development of Sparse Mixture of Experts highlights a clear trend in modern AI, separating model capacity from computational cost.
Instead of scaling the entire system, SMoE enables selective activation, optimizing resource usage while maintaining high performance. This is particularly critical in large-scale systems and continual learning settings.
In the long term, architectures such as SMoE and SMoPE are expected to serve as foundational components for building scalable, adaptive and efficient AI systems in real-world environments.
