

Sparse Mixture of Experts giúp giảm 50% chi phí tính toán, tối ưu tham số và cải thiện hiệu suất học liên tục trong các mô hình AI quy mô lớn.
Sparse Mixture of Experts, biến thể tối ưu hơn của MOE
Trong các hệ thống AI quy mô lớn, bài toán mở rộng dung lượng mô hình mà không làm tăng chi phí tính toán là một thách thức cốt lõi. Kiến trúc Mixture of Experts được thiết kế để giải quyết vấn đề này bằng cách chia mô hình thành nhiều expert, mỗi expert xử lý một phần không gian dữ liệu.
Từ đó, Sparse Mixture of Experts ra đời như một biến thể tối ưu hơn. Thay vì kích hoạt toàn bộ expert, SMoE chỉ chọn một tập nhỏ các expert phù hợp nhất cho mỗi đầu vào. Điều này giúp giữ được dung lượng lớn của mô hình nhưng giảm đáng kể chi phí vận hành.
Một hướng mở rộng quan trọng là Sparse Mixture of Prompt Experts, nơi cơ chế SMoE được tích hợp vào prompt tuning nhằm giải quyết bài toán học liên tục.
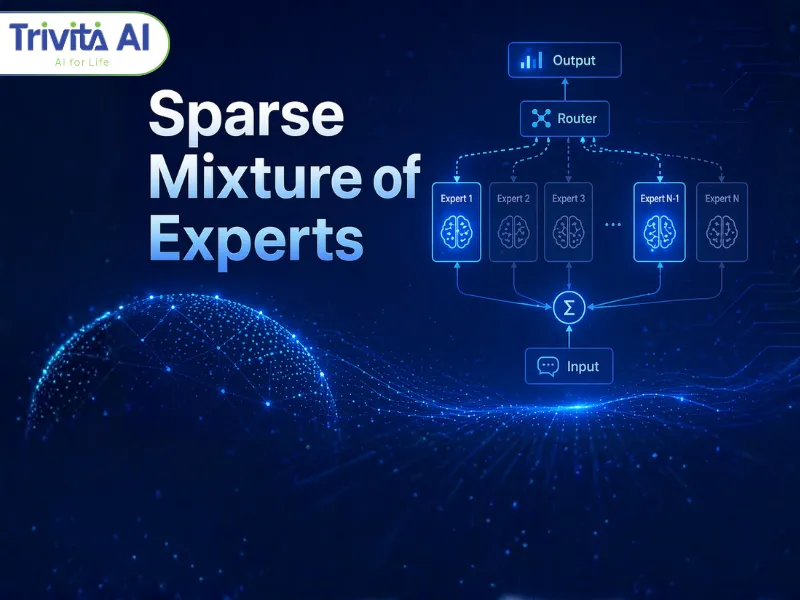
Cách thức hoạt động (Cơ chế vận hành)
Cốt lõi của Sparse Mixture of Experts là cơ chế định tuyến thông minh giữa các expert.
Đầu tiên là cơ chế cổng, đóng vai trò quyết định expert nào sẽ được sử dụng cho mỗi đầu vào. Thay vì xử lý toàn bộ mô hình, hệ thống chỉ kích hoạt một số expert có điểm số cao nhất, thường theo chiến lược Top-K.
Để tối ưu chi phí, SMoE sử dụng cơ chế tổng hợp điểm số, trong đó một đại diện trung bình của đầu vào được dùng để tính toán “proxy score” cho từng expert. Điều này giúp giảm đáng kể độ phức tạp so với việc tính toán trên toàn bộ token.
Ngoài ra, cơ chế nhiễu thích ứng được đưa vào để đảm bảo các expert được sử dụng cân bằng. Nếu không có cơ chế này, hệ thống dễ rơi vào trạng thái chỉ sử dụng một số ít expert, làm giảm hiệu quả tổng thể.
Thông số hiệu suất và tài nguyên của Sparse Mixture of Experts
Các kết quả thực nghiệm cho thấy Sparse Mixture of Experts đạt hiệu quả vượt trội về cả tài nguyên và hiệu suất.
Về số lượng tham số học được, các kiến trúc như SMoPE chỉ sử dụng khoảng 0.38 triệu tham số, thấp hơn đáng kể so với các phương pháp khác như Deep L2P++ với 4.78 triệu tham số hay CODA-Prompt với gần 4 triệu tham số. Điều này cho thấy khả năng tối ưu hóa rất cao trong việc sử dụng tài nguyên.
Về chi phí tính toán, SMoE có thể giảm tới 50% số phép tính cần thiết trong cả huấn luyện và suy luận. Ví dụ, một cấu hình có thể giảm từ khoảng 67.44 GFLOPs xuống còn 33.72 GFLOPs mà vẫn duy trì hoặc cải thiện độ chính xác.
Một điểm quan trọng khác là độ phức tạp tính toán. Nhờ cơ chế proxy score, việc lựa chọn expert được giảm từ bậc O(Ndk) xuống O(dk), giúp hệ thống có thể mở rộng mà không làm tăng chi phí theo số lượng expert.
Cấu hình vận hành tiêu chuẩn của SMoE
Trong các thiết lập thực nghiệm điển hình, Sparse Mixture of Experts được cấu hình với một số tham số quan trọng.
Tổng số expert thường được đặt ở mức 25, trong khi chỉ có 5 expert được kích hoạt cho mỗi đầu vào. Cách tiếp cận này giúp cân bằng giữa dung lượng mô hình và chi phí tính toán.
Các expert thường được tích hợp vào các khối attention đầu tiên của mô hình xương sống, chẳng hạn như các lớp Multi-Head Self-Attention trong kiến trúc Vision Transformer.
Mô hình nền thường sử dụng các phiên bản đã được huấn luyện trước trên các tập dữ liệu lớn, giúp tận dụng tri thức sẵn có và tăng tốc quá trình thích nghi.
Các cơ chế kỹ thuật đặc thù
Một trong những yếu tố giúp Sparse Mixture of Experts đạt hiệu quả cao là các cơ chế kỹ thuật bổ trợ.
Cơ chế nhiễu thích ứng được điều chỉnh ở mức phù hợp, thường khoảng 0.4, giúp cân bằng giữa việc khám phá các expert mới và duy trì sự ổn định của hệ thống.
Cơ chế cổng thưa giúp định tuyến dữ liệu hiệu quả hơn bằng cách sử dụng proxy score thay vì tính toán trực tiếp trên toàn bộ dữ liệu. Điều này không chỉ giảm chi phí mà còn giúp hệ thống ổn định hơn khi mở rộng.

Kết quả thực nghiệm và khả năng ứng dụng
Các kết quả trên nhiều benchmark cho thấy hiệu quả thực tế của Sparse Mixture of Experts.
Độ chính xác đạt mức cao trên nhiều bộ dữ liệu như ImageNet-R với khoảng 79.32%, CIFAR-100 khoảng 89.23% và CUB-200 khoảng 87.43%. Những con số này cho thấy khả năng tổng quát hóa tốt của mô hình.
Ngoài ra, khả năng chống quên lãng là một điểm nổi bật. Trong các kịch bản học liên tục với nhiều tác vụ nối tiếp, SMoE có thể duy trì hiệu suất ổn định mà không bị suy giảm nghiêm trọng, điều mà nhiều mô hình truyền thống gặp phải.
Hướng đi tối ưu cho AI quy mô lớn và học liên tục
Sự phát triển của Sparse Mixture of Experts cho thấy một hướng đi rõ ràng trong AI hiện đại, đó là tách biệt giữa dung lượng mô hình và chi phí vận hành.
Thay vì mở rộng toàn bộ hệ thống, SMoE cho phép kích hoạt có chọn lọc, giúp tối ưu tài nguyên mà vẫn duy trì hiệu suất cao. Điều này đặc biệt quan trọng trong các hệ thống lớn và các bài toán học liên tục.
Trong dài hạn, các kiến trúc như SMoE và SMoPE sẽ đóng vai trò nền tảng trong việc xây dựng các hệ thống AI có khả năng mở rộng, thích nghi và vận hành hiệu quả trong môi trường thực tế.
